Blog
Maschinelles Lernen in Echtzeit: Überlegungen anhand des Anwendungsfalls Betrugserkennung

Wenn es um maschinelles Lernen geht, sind die meisten Produkte so konzipiert, dass sie in Batches arbeiten, d.h. sie verarbeiten Daten in festen Intervallen und nicht in Echtzeit. Dieser Ansatz ist oft einfacher zu verwalten und entspricht in vielen Fällen den Anforderungen des Unternehmens. Es gibt jedoch Situationen, in denen maschinelles Lernen in Echtzeit unerlässlich ist. In diesem Artikel werden wir untersuchen, warum.
Um zu verstehen, warum maschinelles Lernen in Echtzeit so wichtig ist, ist es hilfreich, zunächst die verschiedenen Paradigmen für den Einsatz von maschinellen Lernlösungen zu verstehen.
Batch-Vorhersagen
Nach Angaben von Databricks ist die Batch-Bereitstellung die häufigste Art der Bereitstellung von Modellen für maschinelles Lernen und macht etwa 80-90% aller Bereitstellungen aus. Dabei werden die Vorhersagen eines Modells ausgeführt und zur späteren Verwendung gespeichert. Beim Live-Serving werden die Ergebnisse in einer Datenbank mit geringer Latenz gespeichert, die die Vorhersagen schnell bereitstellt. Alternativ können die Vorhersagen auch in weniger leistungsfähigen Datenspeichern gespeichert werden.

In dieser Phase werden alle Vorhersagen in regelmäßigen Abständen (z.B. täglich) vorberechnet, bevor eine Vorhersageanfrage gestellt wird. Stapelverarbeitungssysteme wie Spark oder MapReduce werden verwendet, um große Datenmengen effizient zu verarbeiten. Durch die Zwischenspeicherung der vorberechneten Vorhersagen entkoppeln wir auch die Berechnung von der Bereitstellung.
Typische Anwendungsfälle für Batch-Prognosen sind die Vorhersage von Abwanderung, Kundensegmentierung und Umsatzprognosen. Für diese Anwendungsfälle sind in der Regel keine Echtzeitdaten erforderlich.
Online-Vorhersagen
Obwohl Echtzeitbereitstellungen einen geringeren Anteil an der Bereitstellungslandschaft ausmachen, umfassen sie oft hochwertige Aufgaben, die einen erheblichen geschäftlichen Nutzen bieten. Echtzeit-Bereitstellungen können entweder Batch-Funktionen oder Streaming-Funktionen verwenden. Es ist wichtig zu wissen, dass Funktionen in Echtzeitanwendungen zwar online verarbeitet werden können, das Training der maschinellen Lernmodelle aber in der Regel im Batch-Modus erfolgt. Dies ist auch zu unterscheiden von einem anderen Bereich, der als Online-ML bezeichnet wird und bei dem nicht nur die Inferenzdaten, sondern auch die Trainingsdaten im Online-Modus eintreffen und spezielle Versionen von ML-Algorithmen kontinuierlich trainiert werden. Dieser letzte Fall fällt jedoch nicht in den Rahmen dieses Artikels.
Batch-Merkmale (statische Merkmale) sind Informationen, die sich selten oder nie ändern, wie z. B. demografische Daten des Kunden (Geburtsdatum, Geschlecht, Einkommen) oder Produktattribute (Farbe, Größe, Produktkategorie und Bilder).
Streaming (Online)-Funktionen hingegen werden aus Streaming-Daten berechnet und basieren auf Echtzeit-Ereignissen. Beispiele hierfür sind aggregierte Streaming-Ereignisse (wie Impressionen, Klicks, Likes oder Käufe), Daten aus sozialen Medien (wie Stimmungsanalysen oder Trendthemen) oder Sensordaten von IoT-Geräten.
Hier sind einige Beispiele für Echtzeit-Anwendungen für maschinelles Lernen:
- Betrugserkennung
Im Bankensektor können Modelle des maschinellen Lernens eingesetzt werden, um betrügerische Transaktionen in Echtzeit vorherzusagen, indem Muster analysiert und Anomalien identifiziert werden. Dieses Beispiel wird in dem folgenden Kapitel ausführlich beschrieben - Produktempfehlungen
In der E-Commerce-Branche sind Produktempfehlungen in Echtzeit äußerst nützlich, da sie sich im Laufe der Zeit an das veränderte Verhalten und die Vorlieben der Nutzer anpassen können. Wenn ein Benutzer auf einer Website ein plötzliches Interesse an einer bestimmten Produktkategorie zeigt, können wir unsere Empfehlungen aktualisieren, um dieses neue Interesse widerzuspiegeln - Dynamische Preisgestaltung
In der Transportbranche können Modelle des maschinellen Lernens die Preisgestaltung auf der Grundlage von Echtzeitfaktoren wie Nachfrage, Wetter oder Verkehrsbedingungen dynamisch anpassen. Wenn die Nachfrage ungewöhnlich hoch ist, wird der Preis entsprechend erhöht. - Vorausschauende Wartung
In der Fertigungsindustrie können Unternehmen anhand von Echtzeitdaten von Sensoren und Geräten vorhersagen, ob eine Wartung erforderlich ist, wodurch Ausfallzeiten reduziert und die Effizienz verbessert werden. Wenn ein Sensor Messwerte außerhalb des normalen Bereichs aufzeichnet, können Warnungen an die Arbeiter gesendet werden, um die Produktionsleitungen zu überprüfen.
Online-Vorhersagen mit Batch-Funktionen
Obwohl Batch-Vorhersagen für die meisten Anwendungsfälle nützlich und ausreichend sind, haben sie viele Einschränkungen. Nehmen wir zum Beispiel eine E-Commerce-Website, die den optimalen Rabatt für einen Benutzer auf der Grundlage der Produkte in seinem Warenkorb vorhersagen möchte. Die Anzahl der möglichen Kombinationen verschiedener Produkte lässt sich nicht vorausberechnen. Ein weiteres Beispiel ist ein Chatbot, dem eine unendliche Vielzahl von Fragen gestellt werden kann, oft mit einer gemischten Reihenfolge von Wörtern. Die Kombinationen und Permutationen von Wörtern und Sätzen sind praktisch unendlich.
Selbst in Anwendungsfällen, in denen alle Vorhersagen im Voraus erstellt werden können, kann es extrem verschwenderisch sein, dies zu tun. Nehmen wir als Beispiel ein Empfehlungssystem, das Artikel für Kunden vorhersagen soll. Die regelmäßige Generierung einer großen Anzahl von Datensätzen wäre nicht nur kostspielig in Bezug auf die Berechnung und Nutzung von Ressourcen, sondern auch zeitaufwändig, da Millionen von Vorhersagen generiert werden müssten. Warum sollten Sie alle Vorhersagen im Voraus erstellen, wenn Sie jede Vorhersage nach Bedarf erstellen können?
Hier kommen die Online-Prognosen mit Batch-Funktionen ins Spiel. Anstatt alle möglichen Vorhersagen im Voraus zu berechnen, bevor die Anfragen eintreffen, werden die Online-Vorhersagen serviert , sobald die Anfragen eintreffen. Dies wird auch als On-Demand-Prognose bezeichnet. Die Online-Bereitstellung kann dazu beitragen, Redundanz zu vermeiden. Zum Beispiel, indem Sie Vorhersagen nur für Benutzer erstellen, die Ihre Website besuchen. 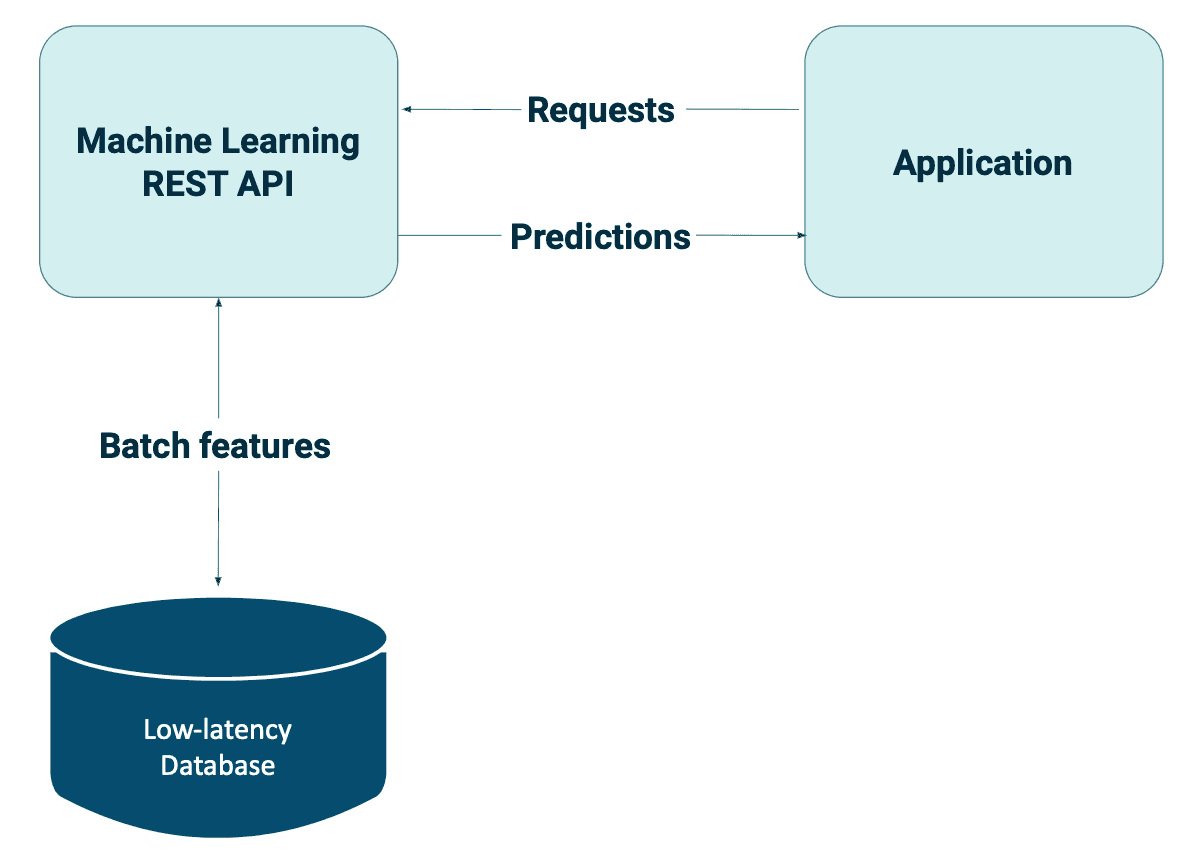
Sehr häufig verwendete Batch-Merkmale für das Online-Serving sind Einbettungen. Beim maschinellen Lernen sind Einbettungen eine Möglichkeit, Daten als Vektoren oder niedrigdimensionale numerische Repräsentationen darzustellen, die die wichtigsten Merkmale der Daten erfassen. Diese numerischen Darstellungen werden oft durch neuronale Netze erlernt und können zur Darstellung einer Vielzahl von Datentypen verwendet werden, wie z.B. Wörter, Bilder oder sogar ganze Dokumente. Durch die Verwendung von Einbettungen können Modelle für maschinelles Lernen komplexe Daten leichter verarbeiten und verstehen, was zu einer besseren Leistung bei Aufgaben wie Klassifizierung, Clustering und Empfehlungssystemen führt.
Die Umstellung Ihrer Modelle von offline auf online bringt jedoch einige Herausforderungen mit sich, von denen die erste die Inferenzlatenz ist. Mehrere Studien zeigen, dass sich Verbesserungen der Website-Geschwindigkeit erheblich auf Geschäftskennzahlen wie die Konversionsrate oder den durchschnittlichen Bestellwert auswirken können. Daher brauchen wir Modelle, die Vorhersagen mit einer angemessenen Geschwindigkeit erstellen können. Es gibt mehrere Möglichkeiten, die Latenzzeit niedrig zu halten. Dazu gehören die Auswahl der informativsten Merkmale, die Vorberechnung von Merkmalen, die Verwendung einfacherer oder kleinerer Modelle, die Verwendung von mehr Rechenressourcen und die Verwendung von Modellquantisierung. Eine weitere Herausforderung ist die Gewährleistung eines ausreichenden Durchsatzes und einer ausreichenden Verfügbarkeit. Sobald Sie Ihr Modell bereitstellen, muss es immer mit einer guten Betriebszeit verfügbar sein.
Wie Sie sehen, kann die Online-Bereitstellung eine der komplizierteren Arten der Bereitstellung von Modellen sein.
Online-Vorhersagen mit Streaming-Funktionen
Statische Funktionen haben auch ihre Grenzen, da sie Ihre Modelle weniger schnell auf sich ändernde Umgebungen reagieren lassen. Der Wechsel zu Online-Vorhersagen mit Streaming-Funktionen ermöglichtIhnen die Verwendung dynamischer Funktionen, um relevantere Vorhersagen zu treffen. Für viele Probleme benötigen Sie sowohl Streaming- als auch Batch-Features, die Sie in einer einzigen Datenpipeline zusammenführen und in Ihre Machine Learning-Modelle einspeisen können.
Streaming-Funktionen sind besonders nützlich in auftragsbezogenen Kontexten, in denen Benutzer Ihre Anwendung mit einem bereits bestehenden Ziel besuchen. Die Bereitstellung der richtigen Inhalte oder Funktionen in Echtzeit ist entscheidend, um sie bei der Stange zu halten und sie davon abzuhalten, zur Konkurrenz zu wechseln.
Nehmen wir an, Sie wollen ein Hotel für Ihren nächsten Urlaub buchen. Sie haben zuvor ein bestimmtes Land besucht, und die Website merkt sich diese Informationen und empfiehlt Ihnen Hotels auf der Grundlage Ihres früheren Reiseziels. Sie möchten jedoch, dass Ihre Empfehlungen auf der Grundlage des aktuellen Kontextes aktualisiert werden, d.h. unter Berücksichtigung aller Änderungen Ihrer Reisevorlieben oder Interessen seit Ihrer letzten Reise. Die Empfehlungen sind möglicherweise nicht so relevant oder nützlich, wenn sich die Website nur auf statische Merkmale wie Ihren bisherigen Reiseverlauf verlässt. In diesem Fall wäre es von Vorteil, dynamische Funktionen einzubauen, die Echtzeitdaten wie Ihren aktuellen Standort, Ihren Suchverlauf und Ihre jüngsten Interaktionen mit der Website berücksichtigen. Auf diese Weise kann die Website persönlichere und aktuellere Empfehlungen geben, die Ihren aktuellen Reisevorlieben besser entsprechen. 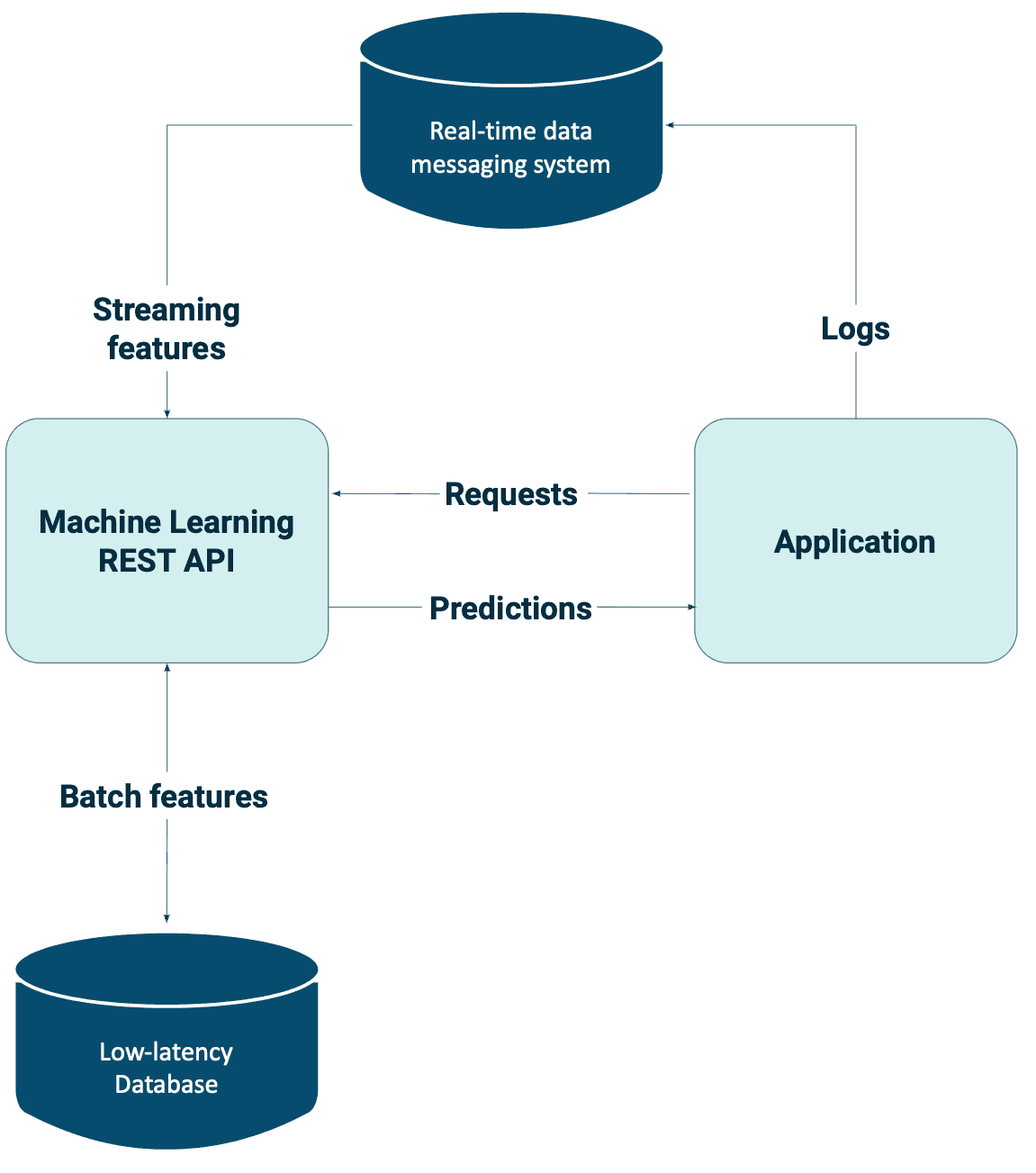
Dennoch erhöht die Einbeziehung von Streaming-Daten die Komplexität Ihrer Anwendungen erheblich. Es wäre hilfreich, wenn Sie über geeignete Echtzeit-Pipelines verfügten, um die Echtzeitvorhersagen aus Streaming-Daten vollständig zu nutzen. Technologien wie Apache Flink oder Apache Kafka ermöglichen die Berechnung von Streaming-Funktionen. Die Verarbeitung von Streaming-Daten stellt jedoch aufgrund der unbegrenzten Datenmenge, die in unterschiedlichen Raten und Geschwindigkeiten eintrifft, eine besondere Herausforderung dar.
Darüber hinaus sind Online-Vorhersagen darauf ausgelegt, Entscheidungen in Echtzeit zu treffen, d.h. sie können sich sofort auf das System oder die Anwendung auswirken, die sie unterstützen. Das bedeutet, dass die Überwachung des Modells auf Fehler oder negative Rückkopplungsschleifen entscheidend ist, um zu verhindern, dass Probleme schnell eskalieren und weiteren Schaden anrichten.
Die Echtzeitverarbeitung mag zwar attraktiv erscheinen, ist aber nur manchmal einfach und kann mit zusätzlichen Kosten und Komplexität verbunden sein. Für viele gängige Anwendungsfälle ist die Stapelverarbeitung ein ausgezeichneter Ansatz, da sie sehr effizient ist. Im Gegensatz dazu ist die Stream-Verarbeitung schnell, denn sie ermöglicht es Ihnen, Daten zu verarbeiten, sobald sie eintreffen. Es ist jedoch wichtig, dass Sie die Nachteile sorgfältig abwägen, bevor Sie sich für echtes Echtzeit-Streaming entscheiden. Tun Sie dies nur, wenn Sie einen geschäftlichen Anwendungsfall gefunden haben, der die zusätzliche Komplexität und die Kosten im Vergleich zur Stapelverarbeitung rechtfertigt.
Wie können Sie maschinelles Lernen in Echtzeit für die Betrugserkennung nutzen? Eine Fallstudie
Lassen Sie uns mit den Definitionen beginnen. Was ist eigentlich Betrugserkennung?
Unter Betrugserkennung versteht man den Prozess der Identifizierung und Verhinderung von betrügerischen Aktivitäten innerhalb eines Systems, einer Organisation oder eines Netzwerks. Betrug kann viele Formen annehmen, wie zum Beispiel:
- Kreditkartenbetrug,
- Versicherungsbetrug
- Identitätsdiebstahl,
- Phishing,
- Internetkriminalität.
Betrügerische Aktivitäten können zu erheblichen finanziellen Verlusten, Rufschädigung und rechtlichen Konsequenzen für Einzelpersonen und Unternehmen führen. Bei der Betrugserkennung kommen verschiedene Methoden und Technologien zum Einsatz, um betrügerische Aktivitäten in Echtzeit zu erkennen und zu verhindern, darunter regelbasierte Systeme und maschinelle Lernalgorithmen. Das Ziel der Betrugserkennung ist es, betrügerische Aktivitäten zu erkennen und zu verhindern , bevor sie Schaden anrichten können, und die Integrität und Sicherheit von Systemen und Organisationen zu gewährleisten.
Wir werden uns auf den Kreditkartenbetrug konzentrieren, da dies die häufigste Form des Betrugs in der Branche ist.
Kreditkartenbetrug ist eine Form des Finanzbetrugs, bei der eine Kreditkarte unberechtigt für Einkäufe oder Bargeldabhebungen verwendet wird. Hier sehen Sie, wie er typischerweise funktioniert, Schritt für Schritt:
- Beschaffung der Kreditkartendaten.
Der Betrüger verschafft sich zunächst die Kreditkartendaten, wie z.B. die Kartennummer, das Gültigkeitsdatum und den Sicherheitscode. Dies kann auf verschiedene Weise geschehen, z. B. durch Diebstahl der physischen Karte, Phishing-Betrug oder Malware-Angriffe auf ein Kassensystem. - Testen der Karte.
Der Betrüger kann dann die Karte testen, um zu sehen, ob sie funktioniert, indem er kleine Einkäufe oder Online-Transaktionen tätigt, um zu sehen, ob die Karte noch aktiv ist und nicht als gestohlen gemeldet wurde. - Betrügerische Einkäufe.
Sobald bestätigt ist, dass die Karte funktioniert, kann der Betrüger sie für größere Einkäufe oder Barabhebungen verwenden. Sie können die Karte verwenden, um Waren oder Dienstleistungen online, per Telefon oder persönlich in einem Einzelhandelsgeschäft oder Restaurant zu kaufen. - Verbergen des Betrugs.
Um den Betrug zu verbergen, kann der Betrüger verschiedene Methoden anwenden, wie z. B. die Änderung der Rechnungs- oder Lieferadresse, die Durchführung mehrerer kleiner Transaktionen oder die Verwendung verschiedener Karten oder Konten für die Einkäufe.
Beispiele für Kreditkartenbetrug können sein:
- die Magnetstreifeninformationen der Karte durch eine Sicherheitsverletzung erlangt werden, wenn die Karte an einem Geldautomaten in einem Einkaufszentrum benutzt wird und dann innerhalb eines kurzen Zeitraums von einem geografisch entfernten Ort aus benutzt wird
- während einer Online-Transaktion werden Kreditkarteninformationen gestohlen, und in der Folge kommt es zu unregelmäßigen Transaktionen mit unterschiedlichen Beträgen oder zu ungewöhnlichen Tageszeiten, nachdem eine gewisse Zeit vergangen ist
- die Kreditkarte wird physisch aus einem Restaurant gestohlen. Kurz nach dem Diebstahl wird eine kleine Transaktion durchgeführt, um die Verwendbarkeit der Karte zu prüfen, gefolgt von einer deutlich größeren Transaktion zu einem späteren Zeitpunkt
- ein übermäßig großer Kauf mit einer Kreditkarte getätigt wurde
- eine Transaktion wurde von einem Ort aus getätigt, der sich von den vorherigen völlig unterscheidet
Infolgedessen werden den Kunden Artikel in Rechnung gestellt, die sie nicht gekauft haben. Es ist wichtig zu wissen, dass Kreditkartenbetrug sowohl für den Karteninhaber als auch für den Kartenaussteller schwerwiegende Folgen haben kann. Kreditkartenbetrug kann schwerwiegende Folgen haben, einschließlich, aber nicht beschränkt auf:
- finanzieller Verlust sowohl für den Karteninhaber als auch für das Finanzinstitut
- Verlust von Vertrauen und Zuversicht der Verbraucher in das Finanzsystem
- Verschlechterung der Kreditwürdigkeit aufgrund unentdeckter betrügerischer Aktivitäten über einen längeren Zeitraum
- rechtliche Folgen für den Karteninhaber, wie z. B. strafrechtliche Anklagen und Geldstrafen, sowie für das Finanzinstitut, das mit rechtlichen Schritten von betroffenen Kunden oder Aufsichtsbehörden rechnen muss
Wenn betrügerische Aktivitäten entdeckt werden, wird der Karteninhaber in der Regel benachrichtigt, und die betrügerischen Transaktionen werden rückgängig gemacht. Der Kartenaussteller kann die Karte auch sperren und dem Karteninhaber eine neue Karte ausstellen. Es ist wichtig, die Kreditkartendaten zu schützen und verdächtige Aktivitäten so schnell wie möglich zu melden.
Wenn betrügerische Aktivitäten entdeckt werden, wird der Karteninhaber normalerweise benachrichtigt und die betrügerischen Transaktionen werden rückgängig gemacht. Der Kartenaussteller kann auch Maßnahmen ergreifen, um die Karte zu sperren und dem Karteninhaber eine neue Karte auszustellen. Es ist wichtig, dass Sie Maßnahmen zum Schutz Ihrer Kreditkartendaten ergreifen und verdächtige Aktivitäten so schnell wie möglich melden.
Warum Echtzeit-ML?
In der heutigen Welt werden Transaktionen fast augenblicklich verarbeitet, was den Kunden ein nahtloses Erlebnis bietet. Allerdings lässt diese Geschwindigkeit der Verarbeitung den Banken und Zahlungsabwicklern auch einen kürzeren Zeitrahmen, um Betrug zu erkennen und zu verhindern. In Fällen von Online-Betrug kann ein Dieb mehrere Transaktionen durchführen, was zu erheblichen finanziellen Verlusten führt. Daher ist es wichtig, dass die Betrugserkennung nahezu in Echtzeit erfolgt. Wenn Sie die Betrugserkennung bis zum nächsten Tag hinauszögern, kann es schwieriger werden, das Geld des Kunden wiederzuerlangen.
Die Betrugserkennung in Echtzeit ist von entscheidender Bedeutung, denn sie ermöglicht es Unternehmen, schnell auf Bedrohungen in Echtzeit zu reagieren und so finanzielle Verluste zu verhindern. Ohne Echtzeit-Erkennung wird Betrug möglicherweise erst entdeckt, wenn bereits ein finanzieller Verlust entstanden ist. Daher ist es unerlässlich, Bedrohungen in Echtzeit zu erkennen und darauf zu reagieren, sobald sie auftreten.
Die Aufdeckung von Betrug ist, ähnlich wie die Cybersicherheit, ein ständiger Kampf zwischen Angreifern (Betrügern) und Verteidigern (Betrugserkennungssystemen). Die Betrüger suchen ständig nach neuen Wegen, um von ihren bösartigen Aktivitäten zu profitieren, während die Betrugserkennungssysteme ständig gefordert sind, ihnen einen Schritt voraus zu sein.
Algorithmen des maschinellen Lernens können die dynamische Erkennung betrügerischer Transaktionen ermöglichen, indem sie große Datenmengen analysieren, um anomale Muster im Zusammenhang mit betrügerischen Aktivitäten zu erkennen. Die Einbeziehung von Streaming-Funktionen in diese Modelle kann deren Reaktionsfähigkeit auf Veränderungen verbessern. Das bedeutet, dass Finanzinstitute und Karteninhaber sofort über verdächtige Transaktionen benachrichtigt werden können, so dass sie schnell Maßnahmen ergreifen können, um weitere betrügerische Aktivitäten zu verhindern.
Im Jahr 2020 erlitten Kreditkartenaussteller, Händler und Verbraucher einen Gesamtschaden von 28,58 Milliarden Dollar durch Kreditkartenbetrug.
Echtzeit-Funktionen können die Leistung unseres Modells erheblich verbessern, was einen großen Einfluss auf die Prävention von Kreditkartenbetrug haben kann. Selbst eine geringfügige Verbesserung der Genauigkeit kann zu erheblichen Einsparungen führen, die sich auf Millionen von Dollar belaufen können! Darüber hinaus erfordern Merkmale im Zusammenhang mit der Betrugserkennung eine Verarbeitung von Echtzeitdaten mit geringer Latenz, um sicherzustellen, dass die Merkmalswerte frisch und aktuell bleiben.
Hier sind einige Echtzeit-Funktionen, die wir berücksichtigen können, um unsere Modelle für maschinelles Lernen zu verbessern:
- die Anzahl der Transaktionen in den X Stunden
- ein plötzlicher Anstieg der Anzahl der Transaktionen innerhalb eines kurzen Zeitraums könnte ein Anzeichen für einen koordinierten Angriff oder eine betrügerische Aktivität sein (wenn ein Betrüger unbefugten Zugriff auf die Kreditkarte erlangt, versucht er in der Regel, so viele Transaktionen wie möglich in kürzester Zeit durchzuführen; er hofft, so viel zu gewinnen, bis die Verteidiger das abnorme Verhalten bemerken)
- die Anzahl der Transaktionen am selben Ort in den X Stunden
- das Auftreten einer Person, die innerhalb eines kurzen Zeitraums mehrere Einkäufe im selben Geschäft tätigt (die Verfolgung der Anzahl der Transaktionen an diesem Ort im Laufe der Zeit kann uns helfen, abnormales Verhalten zu erkennen)
- die Anzahl der eindeutigen Geostandorte in den letzten X Stunden
- die Anzahl der eindeutigen geografischen Standorte, die mit einer Reihe von Transaktionen verbunden sind (dies hilft uns, Transaktionen zu identifizieren, die für einen Menschen unmöglich auszuführen sind; zum Beispiel können Sie nicht in einem Geschäft in London und 15 Minuten später in Tokio einkaufen)
- Zeitunterschied zwischen der letzten Transaktion
- Verhältnis der fehlgeschlagenen Transaktionen in den letzten X Tagen oder die Anzahl der fehlgeschlagenen Transaktionen in Folge (ein höheres Verhältnis der fehlgeschlagenen Transaktionen kann auch auf eine höhere Wahrscheinlichkeit des Diebstahls einer Kreditkarte hinweisen)
- Anträge auf Erhöhung des Kreditkartenlimits in der letzten Stunde
- die Tatsache, dass das Kreditkartenlimit erhöht wird (oft sind Kreditkarten mit niedrigen Limits ausgestattet, so dass Betrüger versuchen können, das Kreditkartenlimit auf einer gestohlenen Karte zu erhöhen, um größere Einkäufe zu tätigen oder mehr Geld zu überweisen)
- die Anzahl der Transaktionen an einem bestimmten Ort
- ein plötzlicher Anstieg der Transaktionen an einem bestimmten Ort, der ein Warnzeichen für betrügerische Aktivitäten sein kann, da Betrüger möglicherweise versuchen, einen bestimmten Ort für ihre betrügerischen Transaktionen zu nutzen; dieses Merkmal kann nützlich sein, um Fälle von organisiertem Verbrechen oder Betrugsringen zu identifizieren, bei denen eine Gruppe von Betrügern ihre Aktivitäten an einem bestimmten Ort oder in einem bestimmten Gebiet koordiniert.
- die Tatsache, ob die aktuelle Transaktion signifikant höher ist als der Durchschnitt der vorherigen Transaktionen
Architektur
Dies ist ein Beispiel dafür, wie ein Echtzeit-Betrugserkennungssystem aussehen könnte.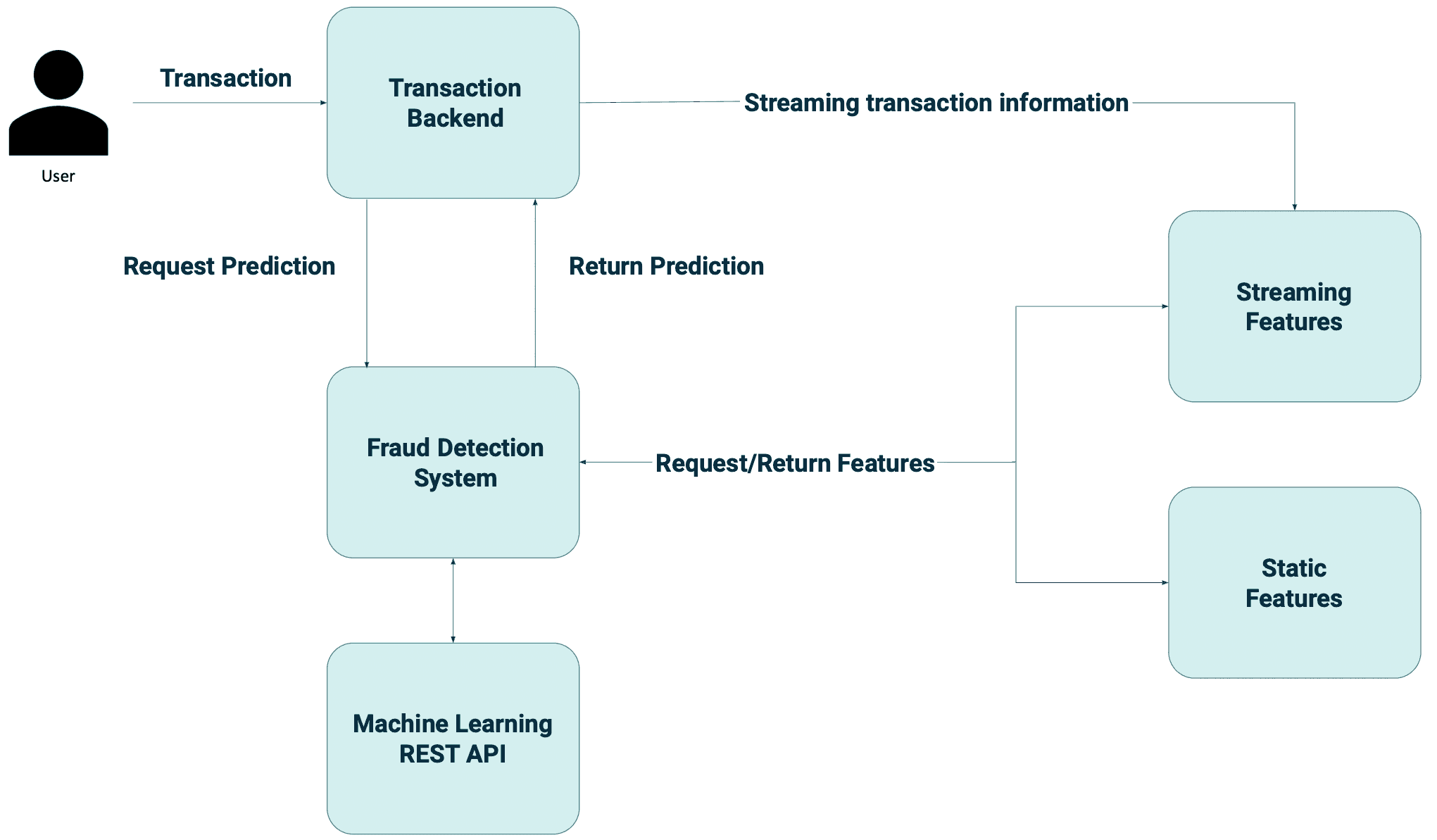
Es würde folgendermaßen funktionieren:
- wenn der Benutzer eine Transaktion mit seiner Kreditkarte durchführt, werden die Transaktionsinformationen an das Transaktions-Backend gesendet
- Von dort aus werden die Informationen sowohl an:
das Betrugserkennungssystem
die Streaming-Technologie - das Betrugserkennungssystem fordert Funktionen sowohl aus der Online-Datenquelle (Streaming) als auch aus der Offline-Datenquelle (Batch) an
- Streaming-Datenbank mit niedriger Latenz enthält Echtzeit-Funktionen
- Offline-Datenbank enthält statische Merkmale wie Informationen über den Shop und den Benutzer
- Nachdem das Betrugserkennungssystem die erforderlichen Merkmale erhalten hat, sendet es eine Anfrage an die REST-API für maschinelles Lernen, die ein trainiertes Modell verwendet, um vorherzusagen, ob die Transaktion betrügerisch ist oder nicht.
- die Vorhersage wird dann an das Betrugserkennungssystem zurückgegeben, das die Ergebnisse an das Transaktions-Backend weiterleitet
Die Software-Infrastruktur muss so konzipiert sein, dass sie ein hohes Volumen an Transaktionen bewältigen kann. Das System muss außerdem fehlertolerant und skalierbar sein, um sicherzustellen, dass es einen erhöhten Datenverkehr bewältigen kann. Darüber hinaus ist es wichtig, über geeignete Überwachungs- und Warnsysteme zu verfügen, um eventuell auftretende Probleme zu erkennen und zu beheben.
Zusammenfassung
Insgesamt ist die Erkennung in Echtzeit für die Prävention von Kreditkartenbetrug von entscheidender Bedeutung, da sie es Privatpersonen und Unternehmen ermöglicht, schnell auf betrügerische Aktivitäten zu reagieren, finanzielle Verluste zu begrenzen und den unbefugten Zugriff auf Gelder zu verhindern. Dies kann dazu beitragen, weitere betrügerische Aktivitäten zu verhindern, finanzielle Verluste zu begrenzen und die Chance zu erhöhen, verlorene Gelder wiederzuerlangen.
Interessieren Sie sich für ML- und MLOps-Lösungen? Wie können Sie ML-Prozesse verbessern und die Lieferfähigkeit von Projekten steigern? Melden Sie sich für eine kostenlose Beratung an.
Unsere Ideen
Weitere Blogs

Contact